지난 시간에 데이터베이스 실기에서 정말 기초가 되는 관계 대수를 살펴보았습니다.
이번 시간에는 SQL 쿼리문을 살펴볼 것이고, 그 중에서도 SELECT문의 문법을 살펴볼 것입니다.
SQL(Structured Query Language)은 데이터베이스 관리 시스템(DBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어입니다. 이는 다음과 같이 세 가지로 분류됩니다.
1) 데이터 정의 언어 (DDL, Data Definition Language)
데이터베이스 내에 테이블을 생성(CREATE), 변경(ALTER), 삭제(DROP) 하거나 권한의 부여(GRANT)나 박탈(REVOKE), 주석(COMMENT), 자료의 버림(TRUNCATE) 등을 수행하는 명령문이 있습니다.
2) 데이터 조작 언어 (DML, Data Manipulation Language)
테이블 내에 데이터를 삽입(INSERT), 수정(UPDATE), 조회(SELECT), 삭제(DELETE)하거나 테이블에 잠금을 설정하거나 (LOCK TABLE), SQL문의 처리 절차에 대한 정보를 얻거나 (EXPLAIN PLAN), PL/SQL 모듈을 호출하는 작업(CALL) 등을 수행하는 명령문이 있습니다.
3) 데이터 제어 언어 (DCL, Data Control Language)
트랜잭션의 성격을 제어하는 것으로서 SET TRANSACTION, COMMIT, ROLLBACK, SAVEPOINT 등의 명령문이 있습니다.
이제 본격적으로 SELECT문을 자세히 살펴보겠습니다.
SELECT문은 아래와 같이 구성되어 있습니다.
(빨강색 - 필수 구문, 검정색 - 옵션)
SELECT (attributes)
FROM (tables)
[ WHERE (conditions) ]
[ GROUP BY (attributes) ]
[ HAVING (conditions) ]
[ ORDER BY (attributes) (ASC/DESC) ]
1) SELECT (attributes) FROM (tables)
- "(tables) 테이블에서 (attributes) 부분의 값을 보여준다." 라고 해석할 수 있습니다.
- 관계 대수의 '프로젝션(π)'을 떠올리시면 됩니다.
① attributes: 테이블 내의 칼럼명(들)을 의미합니다.
② tables: 테이블명을 의미합니다.
- 여러 개의 테이블명을 ','로 구분하여 기재하는 것도 가능합니다. 여기서 콤마(,)는 '카티션 곱(×)' 이라고 생각하시면 됩니다.
- 콤마 이외에 JOIN, NATURAL JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, CROSS JOIN 등의 명령어를 사용하는 것도 가능합니다.

'학생_테이블' 에서 'ID1', '이름' 부분을 보여줍니다.

학생_테이블과 취미 테이블을 조인한 상태에서 '이름', '취미' 부분을 보여줍니다.
2) WHERE (conditions)
- "테이블 내에서 (conditions) 조건을 만족하는 값을 보여준다."
- 관계 대수의 '셀렉션(σ)'을 떠올리시면 됩니다.
① conditions: 값들을 필터링하기 위한 조건(들)을 의미합니다.
- 조건 하나마다 비교 연산자(=, <>, !=, >=, <=, >, <)가 들어가야 되고, 논리 연산자 NOT을 씌우는 것도 가능합니다.
- 조건이 여러 개일 경우 논리 연산자 AND, OR를 사용해야 됩니다.
- 크다, 작다 등의 연산자는 숫자 뿐만 아니라 문자열 비교도 가능합니다. (아스키 코드 사용)
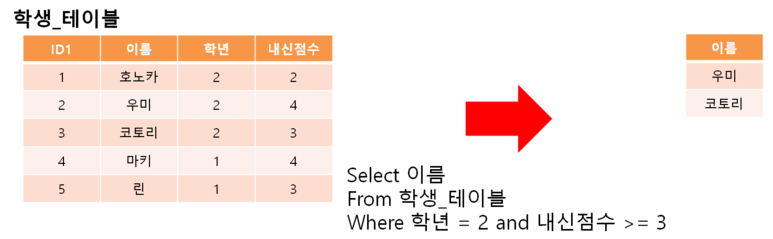
2학년이고 내신점수가 3 이상인 명단을 보여줍니다.
3) GROUP BY (attributes) HAVING (conditions)
- "(attributes) 기준으로 테이블을 그룹핑한다. 그리고 집계함수를 사용했을 때 (conditions) 조건을 만족하는 값만 보여준다."
① attributes: 테이블을 그룹핑(Grouping)하기 위한 기준을 의미합니다.
- 서로 같은 값을 하나로 통일한 다음, SELECT 절에서 집계함수(COUNT, SUM, AVG, MIN, MAX)를 사용해 산수 및 연산을 진행합니다.
- '그룹핑을 하려면 집계함수를 사용해 표현해야 된다' 라는 문장은 참이지만, 이의 역은 성립하지 않습니다.
- 다시 말해, 집계함수를 사용하려면 반드시 그룹핑을 해야 되는 것은 아닙니다. 전체 값에 대해 산수 및 연산을 진행할 수 있기 때문입니다.
② conditions: '집계함수'를 사용했을 때 값들을 필터링하기 위한 조건(들)을 의미합니다.
- 집계함수를 사용하지 않는다면 WHERE 절에 조건을 기재하고, 사용하면 HAVING 절에 기재합니다.

학년 기준으로 테이블을 그룹핑하여, 학년 별 내신점수 평균을 구합니다.

전체 학생 내신점수 평균을 구합니다.

학년 내에 학생 수가 3 이상이라는 조건 하에, 학년 별 내신점수 평균을 구합니다.
4) ORDER BY (attributes) (ASC/DESC)
- "(attributes) 기준으로 출력 결과를 오름차순 또는 내림차순으로 정렬한다."
① attributes: 출력 결과를 정렬하기 위한 기준(들)을 의미합니다.
- 여러 개의 칼럼명을 기재하는 것도 가능합니다. 앞부분에 나와있는 칼럼명부터 기준 삼아 정렬해나갑니다.
- 예를 들어 'ORDER BY A, B, C' 이면, 우선 A 기준으로 정렬하고 A 값이 같은 값들끼리 B 기준으로 정렬하고 B 값이 같은 값들끼리 C 기준으로 정렬하는 것입니다.
② ASC/DESC: 오름차순으로 정렬할 것인지, 내림차순으로 정렬한 것인지를 의미합니다.
- 이 부분은 생략 가능하며, 생략 시 오름차순으로 정렬됩니다.
- ASC: 오름차순 정렬 (default)
- DESC: 내림차순 정렬

학생 명단을 '학년' 기준으로 오름차순 정렬한 다음, 학년이 같은 값들끼리 '이름' 기준으로 정렬해서 보여줍니다.
이 외에 LIMIT, TOP 절도 존재하지만, 중요한 부분은 아니므로 생락하겠습니다.
다음 시간에는 SELECT문 이 외에 여러 가지 쿼리문(INSERT, UPDATE, DELETE 등)을 살펴볼 것입니다.
후에는 Java와 DB를 서로 연동해보는 JDBC 실습도 진행할 것입니다.
'IT강의 > 데이터베이스' 카테고리의 다른 글
| 2018년도 정보처리기사 실기 2회 문제풀이 및 해설 - 5. SQL 쿼리문 (0) | 2020.12.27 |
|---|---|
| 2018년도 정보처리기사 실기 2회 문제풀이 및 해설 - 4. 데이터베이스 이론 (0) | 2020.12.27 |
| DB 연동 및 SQL 응용 - JDBC (0) | 2020.12.26 |
| SQL - 데이터 조작어 (0) | 2020.12.26 |
| 관계 대수 (0) | 2020.12.26 |